Using AI to Improve the Foodnoms Food Database

In 2020, I wrote that a food tracking app "ultimately lives or dies by its database". At the time, Foodnoms was only a few months old, and I had been considering how to improve and grow the food database. In the post, I explained why I chose to build a crowdsourced food database instead of licensing expensive third-party data.
Six years later, thanks to over 500,000 user submissions and corrections, that database has grown to 750,000 unique foods. But the work of maintaining and improving the database never stops.
New submissions typically come from a user after they scan a barcode and the associated nutrition label (previously using on-device OCR, now using an LLM-powered server call).
The biggest problem with crowdsourcing is data quality. User submissions shouldn’t be immediately trusted, otherwise the database will be filled with incorrect and noisy data. Moderating submissions is hard to scale, especially on an indie budget, but I felt strongly that ultimately going the crowdsourced route was the right move.
I initially tried manual review: painstakingly reviewing every single submission one at a time. That didn’t last long. Then I hired a college student to work on it part-time for a couple years. After they graduated, I failed to find a replacement and the backlog of submissions started to grow.
In early 2025, I finally addressed the growing backlog by building a new moderation system where GPT-4o analyzed foods and a human moderator made the final moderation decision. It worked significantly better than the previous system, as now foods were being moderated in bulk. And I found a new moderator who made great progress making a dent in the backlog, finally! That was working out well until he ended up getting a new opportunity a few months later. I was back to where I was before: foods were going unmoderated and the backlog was growing. I looked for a replacement, but nobody was interested in such tedious work.
Going Fully Autonomous with Moderation
Earlier this year, I finally accepted there was no realistic human-powered path to solving this problem. The backlog was too large and the work was simply too tedious. I felt this was one area where AI is really a great fit. The question was: is AI capable enough of doing a good job? Had models become capable enough to fully take over and make the moderation decisions, not just recommend them?
To answer this question, I started by running a model comparison with real and synthetic food data across GPT-4o-mini, Claude Sonnet 4.5, GPT-4o, and Gemini 2.5 Flash. Gemini 2.5 Flash was the clear winner with 96.8% accuracy and zero false positives. Most importantly, it was significantly cheaper than the alternatives.
At this point, I made a few key design decisions:
Synchronous over batch. The previous system used OpenAI's Batch API for a 50% cost discount, but it required a three-step pipeline (create batches, poll for completion, process results), S3 coordination, and batches could take up to 24 hours. Regular Gemini calls were cheaper per token than even batched OpenAI, and the result was simpler, cheaper, and faster all at once. Batch API discounts are a trap when the cheaper model is already cheaper.
Web search for brand verification. Many submissions were missing the brand field, which would have meant instant rejection. Other submissions had the wrong brand or product name. The new system runs a few web searches to try to recover or validate these fields. This salvages data that would have been otherwise rejected, and improves the overall quality of the data.
Selective approval. Instead of rejecting an entire food because one micronutrient looks wrong (say, potassium is wildly off), approve it with that nutrient set to null. Essential fields like name, brand, calories, and macros still trigger full rejection.
I didn't flip the switch to full autonomy right away. The system staged results for review, and I personally checked the AI's reasoning, its approve/reject decisions, and its corrections. After I was happy with 99% of decisions, I removed the manual confirmation step. I still spot-check results daily, but the system is running fully on its own.
Fixing Generic Food Search
Foodnoms has two kinds of food data: branded foods (e.g. Doritos, Cheerios) with barcodes and generic foods (e.g. chicken breast, rice, strawberries) without barcodes. Barcode scanning is popular, but searching is actually the more common way people find foods, and it's the only way to find generic foods.
Now that I finally solved the branded data problem, I shifted my attention to the generic side of things.
For this project, I started with Claude Code. I wanted to start with breaking down and identifying all the problems before trying various specific solutions. I instructed Claude to simulate a user study where various AI personas each logged a full day of meals using the Foodnoms search engine. The personas rated the search results across several dimensions: relevance, result quality, nutritional accuracy, portion options, and naming clarity. This gave me an overall baseline that I could work off of. More importantly, it gave me insight into some really poor-performing queries that weren’t on my radar. Eventually, this grew into a reusable eval framework that I was able to use to benchmark different experiments against each other.
Now that we had identified a series of user-facing problems, I used Claude to come up with some experiment ideas for each kind of problem. Some experiments turned into wins, while others didn't pan out as expected.
The first big win was stemming. This made queries like "eggs" match "egg,” and "blueberry" match "blueberries." Previously, typo correction would help here, but stemming is a better solution to the problem and frankly should have been enabled long ago (in my memory it had been, but things slip through the cracks when maintaining everything solo).
The second win was removing a bunch of noisy foods from the database that were polluting search results and making certain items difficult to find.
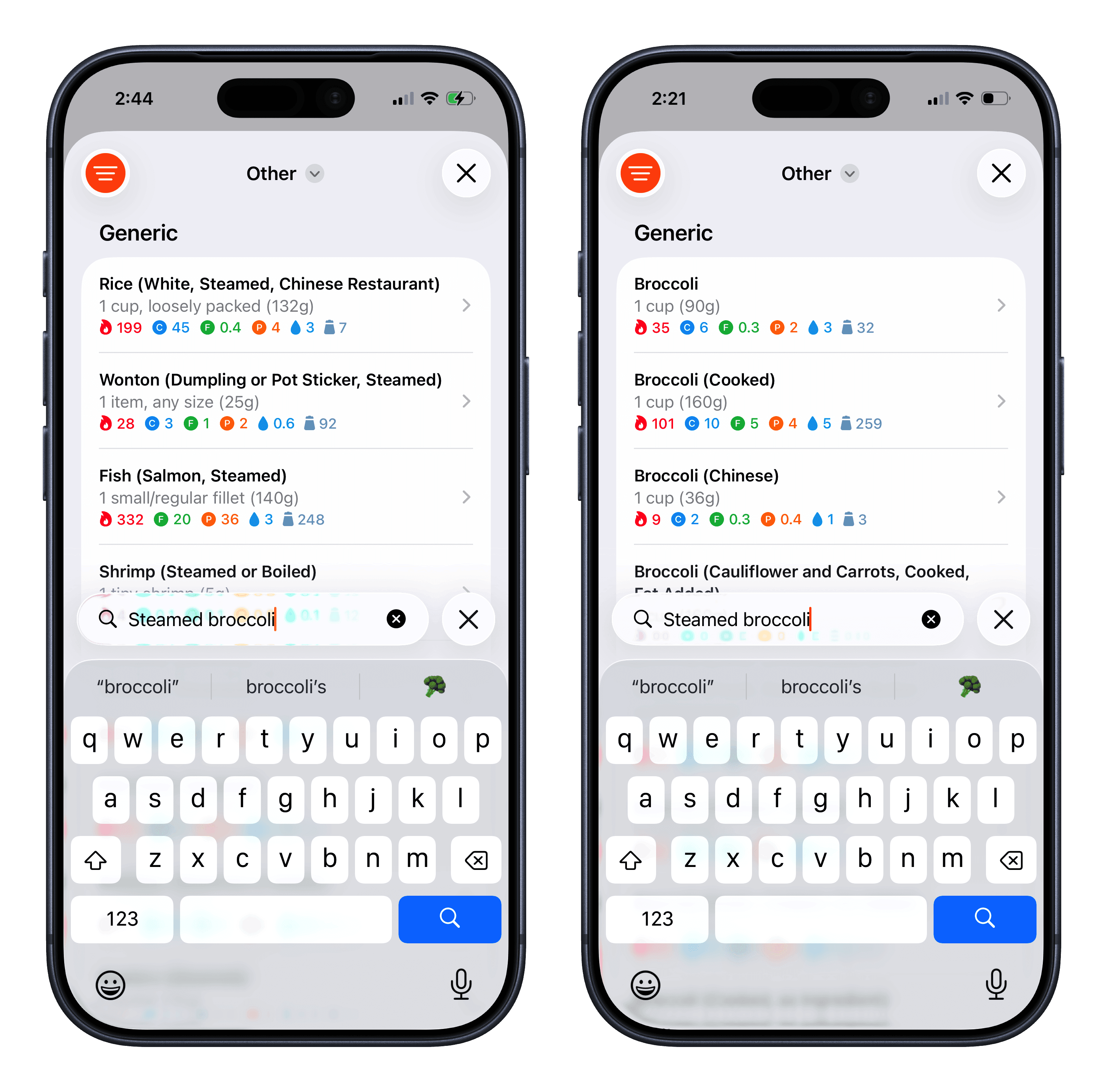
The next problem was more challenging to solve. In the simulated user study, one of the AI personas searched for "steamed broccoli" and the top results were for steamed rice, wontons, and fish. There's no "steamed broccoli" entry specifically, but there are several broccoli entries: raw, cooked, frozen, etc. The search engine just didn’t include them in the search results. It was silently dropping words when too few results matched all of them, so it served items containing "steamed" and effectively ignored "broccoli" from the query. Obviously this is not ideal behavior, as someone who is searching for broccoli isn’t expecting to see rice and fish.
The first experiment to solve this problem was to leverage vector embeddings. The idea was that it would semantically understand that queries for steamed broccoli are more similar to broccoli items. In practice, embeddings worked great for some kinds of queries, but ended up making others worse. I ended up opting for a different approach: using an LLM to generate a list of keywords and synonyms for each food at ingestion time. This keeps search fast and easier to predict, and the preprocessing cost is a one-time expense per food rather than a per-query cost.
Improving Generic Food Data
After squeezing what I could out of search ranking, the next level of improvement required dealing with issues with the data itself.
Historically, all of the generic food data came from the USDA, which is a great foundation: it's free, lab-measured, and covers a wide range of foods. That said, it's not perfect. Some nutrition values are modeled rather than measured, naming conventions are sometimes verbose or clinical, and coverage of international foods is thin. Since the beginning, the Foodnoms database treated USDA data as immutable: import it once, transform it, serve it, and don't touch it until the USDA releases a new version of the dataset.
I recognized that it was time to take a different approach. The USDA is the core of the database and contributes enormously, but for a consumer app like Foodnoms, a certain amount of curation and editing is required to achieve the best UX.
So I rebuilt the system to allow for more manual curation of the USDA data. Now I can selectively hide wrong foods, correct individual values, add new generic foods from other sources. Instead of "wait for the next USDA release," issues can now be fixed in minutes and the search index updates immediately.
Another area of focus was spotting foods that were categorically missing from the USDA dataset. To find these missing foods systematically, Claude and I built a hierarchical taxonomy of about 1,500 generic food tags, and tagged all items in the database. Then it was trivial to generate a report of all of the unused tags, representing gaps in the database. This list included a few hundred common dishes and a few key ingredients including chicken tikka masala, ponzu sauce, muesli, pancetta, matcha, and coq au vin.
To fill the worst gaps, I selectively imported data from three international food databases: CIQUAL (France), CoFID (UK), and MEXT (Japan).
A New Admin UI
A lot of infrastructure work happened alongside the product work, but the one worth calling out is the admin UI. I vibe-coded this web app with React 19, Vite, TanStack Router, Tailwind CSS v4, and shadcn/ui. This UI replaced Interval, which was acquired and shut down in 2023.
Interval's value prop was making it easy for engineers to build internal tools, but it was limited in components. These days it's so simple to vibe-code a frontend that there are fewer compromises.
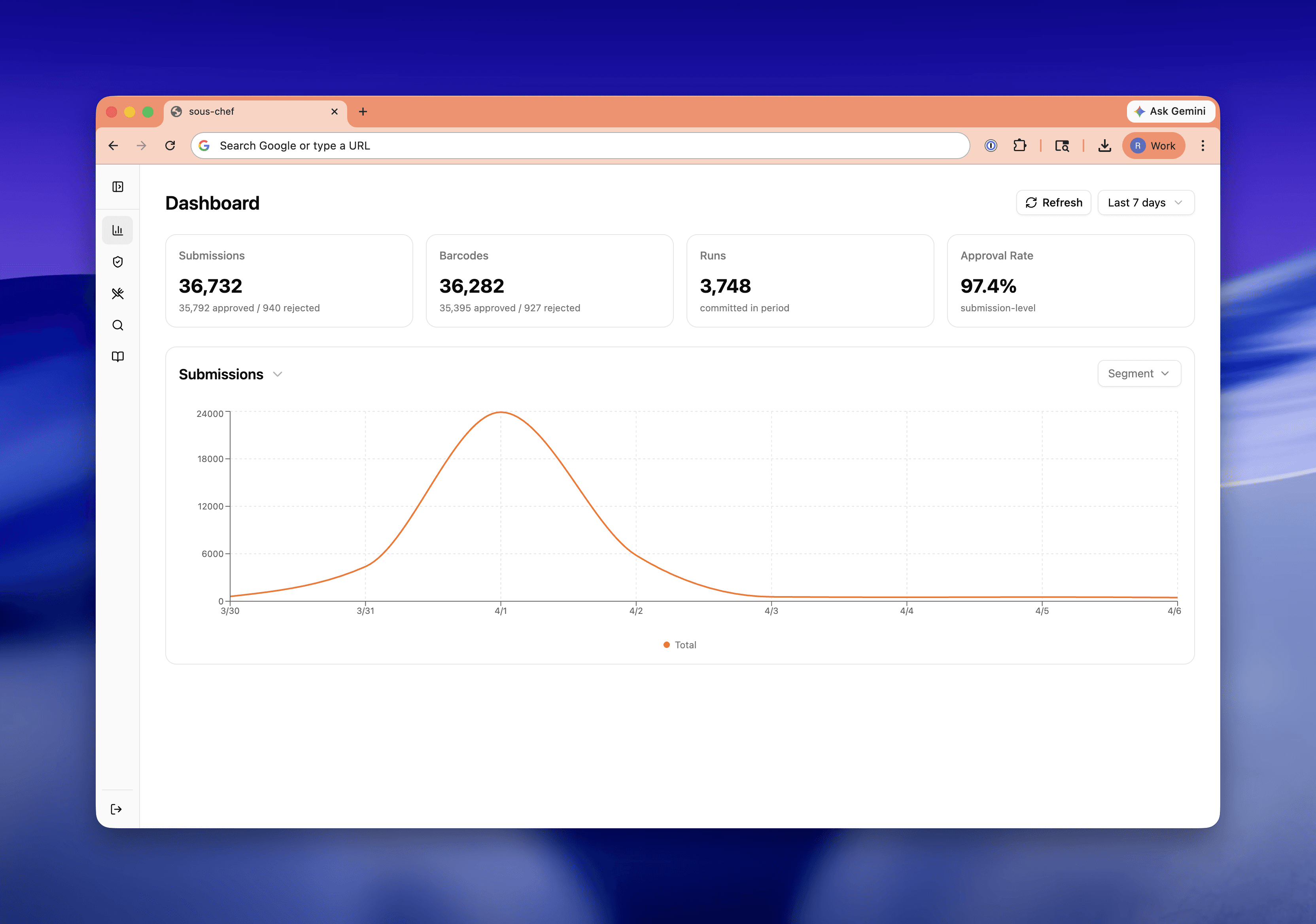
I’m really happy with this new admin panel, which has already grown into a platform for various tools that help me monitor and curate the database.
A few months ago, I wouldn't have predicted I'd be able to tackle these problems. It's a relief to have finally addressed them, and I know it wouldn't have been possible without the latest Claude and Gemini models.
I’m thrilled to share that there's tangible user impact already:
US barcode scan success has risen from 85% to 91%. Worldwide success rate is up from 80% to 87%.
The moderation backlog is zero for the first time ever.
New submissions are reviewed within minutes.
The generic food catalog is broader and more accurate than it's been at any point in Foodnoms' history, and when something is wrong, I can fix it the same day.
There's still plenty of opportunity ahead: adding more restaurant foods, adding more international dishes, and localization.
Six years after writing that a food app "lives or dies by its database," I finally feel like the Foodnoms database is firing on all cylinders and living up to its original promise.